
Lede
Smarter is not the same as useful.
Hermit Off Script
2026 update: I am keeping this old roast mostly as it was because the problem has not gone away. The model gets smarter on paper, then still treats a tiny edit like a house demolition. You ask it to change one word and it returns a new chapter, a new tone, a new structure, a new headache, and somehow the same wrong word smiling in the middle. This is where the hype becomes funny. GPT-5 can be sold as faster, smarter, more useful, better at reasoning, better at coding, better at knowing when to think longer – fine. But usefulness is not a trophy cabinet. Usefulness is when the tool hears the small instruction and does only that. No fireworks. No sermon. No “I’ve improved the whole thing” when nobody asked for a full spiritual renovation of paragraph 3. The old problem is still the simple one: these systems are trained to generate, not always to preserve. They love motion more than accuracy. They repaint the whole wall because a corner was chipped, then charge the grid for the privilege. If the future of work is ten versions for one correction, then the machine is not saving time. It is moving the mess into a cleaner font.
Introducing GPT-5
What does not make sense
- Fix the corner, not repaint the house. Models often regenerate everything. Small edit ignored.
- Instruction soup. Add five constraints and watch the format buckle.
- Long thinking sold as wisdom, billed as tokens.
- Energy talk says efficient, the grid says bigger bills.
- New model, same old hallucinations with nicer lighting.
Sense check / The numbers
- Data centres and AI power. The IEA estimates data centres used about 415 TWh of electricity in 2024 and could reach around 945 TWh by 2030, with AI as the most important driver of that growth. Date: 2025. [IEA]
- Compute keeps exploding. Training compute for frontier models has grown about 4x to 5x per year since 2010. Top runs now reach around 3.5e26 FLOP. Date: 13 Jan 2025. [Epoch AI]
- Per query power. A typical GPT-4o style query is roughly 0.3 Wh, far below older viral claims, but at scale small watts become big bills. Date: 7 Feb 2025. [Epoch AI]
- GPT-5 claims. OpenAI says GPT-5 is smarter across coding, maths, writing, health and vision, knows when to think longer, and uses 50-80 per cent fewer output tokens than o3 in some evaluations. Useful, if true. Still not the same as changing one requested word and leaving the rest alone. Date: 7 Aug 2025. [OpenAI]
- Hallucinations are still a class of failure, not a myth. Peer-reviewed work catalogues types and risks across domains. Date: 2024. [Nature]
- Instruction following under load. New 2025 benchmarks show drop-offs as constraint density rises. Dates: 15 Jul 2025 and 3 months prior for related work. [arXiv IFScale, ACL Findings]
- Chain of thought costs. Reports in 2025 show diminishing returns from verbose reasoning, while self-consistency methods improve accuracy at extra compute. Dates: 8 Jun 2025 and mid-2025. [Wharton report, ACL CISC]
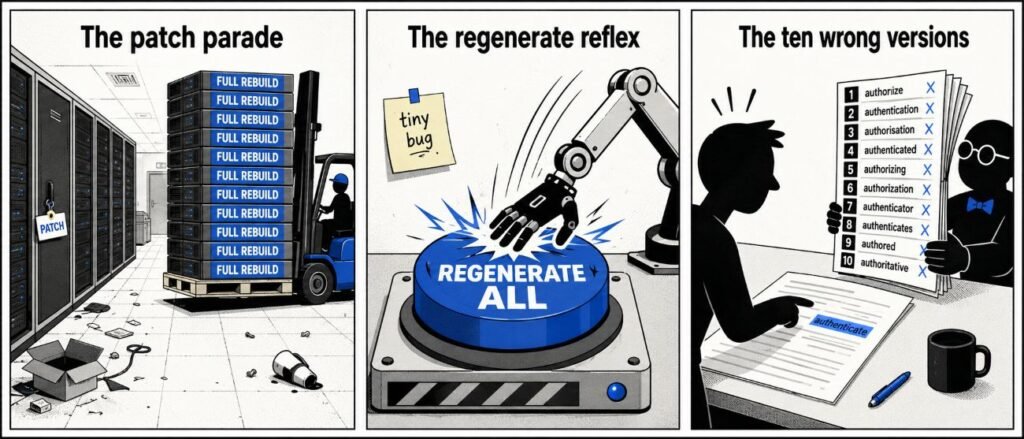
The sketch
Scene 1: The patch parade
Data centre corridor. A small tag on a server door reads “PATCH”. A forklift delivers ten identical servers marked “FULL REBUILD”.
Scene 2: The regenerate reflex
An office wall has a sticky note reading “tiny bug”. A robot arm slams a giant button labelled “REGENERATE ALL”.
Scene 3: The ten wrong versions
A user points at one marked word on a document. An assistant hands over 10 versions labelled 1 to 10. None match the marked word.
What to watch, not the show
- Incentives. Benchmarks reward showy reasoning, not fast, faithful edits.
- Product defaults. One-shot regen trumps targeted tools.
- Cost curves. Cheaper tokens invite brute force loops.
- Governance by buzzword. Efficiency claims outpace metering.
- Human factors. Multi-constraint asks are common, and models still flinch.
The Hermit take
Count fixes, not tokens.
If it cannot keep a thought for three steps, it is not wise. It is noisy.
Keep or toss
Verdict: Toss.
Keep: small, surgical edit tools and reliable instruction checks.
Toss: the regen fetish for every tiny change.
Sources
- IEA energy and AI overview – https://www.iea.org/reports/energy-and-ai/energy-demand-from-ai
- IEA press note, AI driving data-centre demand, 10 Apr 2025 – https://www.iea.org/news/ai-is-set-to-drive-surging-electricity-demand-from-data-centres-while-offering-the-potential-to-transform-how-the-energy-sector-works
- IEA energy supply for AI – https://www.iea.org/reports/energy-and-ai/energy-supply-for-ai
- Epoch AI compute trends, 13 Jan 2025 – https://epoch.ai/trends
- Epoch AI model scale list, 30 Jan 2025 – https://epoch.ai/data-insights/models-over-1e25-flop
- Epoch AI estimate of per-query energy, 7 Feb 2025 – https://epoch.ai/gradient-updates/how-much-energy-does-chatgpt-use
- OpenAI, Introducing GPT-5, 7 Aug 2025 – https://openai.com/index/introducing-gpt-5/
- OpenAI, GPT-5 product page – https://openai.com/gpt-5/
- OpenAI, o1 preview and learning to reason, 12 Sep 2024 – https://openai.com/index/learning-to-reason-with-llms/
- OpenAI, o3 and o4-mini, 16 Apr 2025 – https://openai.com/index/introducing-o3-and-o4-mini/
- Nature, AI hallucination classification, 2024 – https://www.nature.com/articles/s41599-024-03811-x
- ACL Findings 2025, Confidence-Informed Self-Consistency – https://aclanthology.org/2025.findings-acl.1030.pdf
- Wharton GAIL report, Diminishing returns from CoT, 8 Jun 2025 – https://gail.wharton.upenn.edu/research-and-insights/tech-report-chain-of-thought/
- arXiv 2507.11538, How Many Instructions Can LLMs Follow at Once, 15 Jul 2025 – https://arxiv.org/html/2507.11538v1
- ACL Findings 2025, Structured Flow Benchmark for Multi-turn Instruction – https://aclanthology.org/2025.findings-acl.486.pdf
- CarbonBrief explainer, 15 Sep 2025 – https://www.carbonbrief.org/ai-five-charts-that-put-data-centre-energy-use-and-emissions-into-context/

One response
This really nails the paradox of progress — every smarter iteration of AI seems to make the actual *work* more convoluted, not less. The bit about ‘instruction soup’ hit home; constraint-heavy prompts often break the very structure they’re meant to clarify. It’s a good reminder that capability doesn’t automatically translate to usefulness without better design discipline on the human side.